

Este cuarto trimestre del año viene con muchísimas mejoras y cambios en Oracle Autonomous Database. Vamos a analizarlas una por una a continuación.
Mejoras de Octubre de 2022
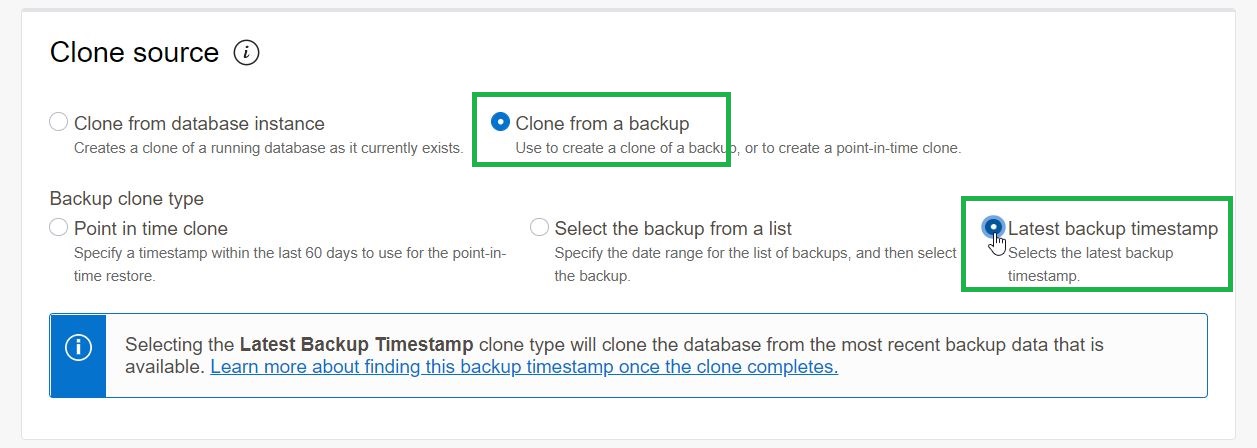
Clonar Base de Datos Autónomas a Partir de un Backup
Ahora es posible generar un clon de una base de datos directamente desde un backup de la misma (en caso que la base deseada ya no se encuentre disponible o sencillamente porque se desea hacer desde el ultimo backup disponible.
Para ver más detalles se puede consultar la documentación oficial.
Usar Claves de Cifrado guardadas en otro Tenancy
Si se utilizan claves de cifrado propias (no generadas por Oracle) es posible elegir las mismas desde una Vault de otra tenancy (mientras sea en la misma región). Al momento de elegir el como administrar las claves de encriptado al crear una Base de Datos Autónoma, una nueva opción es presentada:

Uso de "Google Service Account" para Acceder a Recursos de Google Cloud Platform
Ahora es posible usar una cuenta de servicio de Google para acceder a recursos de GCP.
Para ver más detalles se puede consultar la documentación oficial.
Parámetro SYSDATE_AT_DBTIMEZONE
El parámetro SYSDATE_AT_DBTIMEZONE permite ver la fecha y la hora según la zona horaria predeterminada de la base de datos autónoma, la hora universal coordinada (UTC), o según la zona horaria que establezca en su base de datos (mencionamos esto en el articulo de mejoras del primer trimestre de 2022). Ahora es posible configurar este parámetro tanto a nivel de sistema como a nivel de sesión.
Para ver más detalles se puede consultar la documentación oficial.
Ver Acciones Realizadas por Oracle en la Base de Datos Autónoma
Una nueva vista llamada "DBA_OPERATOR_ACCESS" incluye información sobre las acciones que Oracle Cloud Infrastructure realiza en la base de datos.
La misma incluye las siguientes cuatro columnas:
- SQL_TEXT: Texto de la sentencia SQL ejecutada por Oracle Cloud.
- EVENT_TIMESTAMP: Momento en que fue ejecutada la sentencia.
- REQUEST_ID: Puede ser un número de Bug, número de Service Request en Oracle Support o un número de ticket que generó la ejecución de la tarea.
- REASON: Breve descripción del motivo por el cual se ejecuta la tarea, puede ser "MITIGATION", "DIAGNOSTIC COLLECTION" o "CUSTOMER REQUEST".
Para ver más detalles se puede consultar la documentación oficial.
Mejoras de Noviembre de 2022
Carga y Descarga de archivos en Paralelo
El paquete PL/SQL DBMS_CLOUD permite realizar tareas de carga, descarga, copia y transferencia de archivos masivos en paralelo, mejorando notablemente el tiempo requerido para estas actividades.
Para ver más detalles se puede consultar la documentación oficial.
Use el índice de texto en el almacenamiento de objetos
Se puede crear un índice de Oracle Text en archivos de almacenamiento de objetos. Esto permite hacer búsquedas por texto en el almacén de objetos y usar comodines con su búsqueda.
Para ver más detalles se puede consultar la documentación oficial.
Clones Refrescables entre Distintas Regiones
Ahora es posible crear un clon refrescable de una base de datos autónoma en una region distinta a la base de datos origen. En el siguiente ejemplo, vemos la opción de seleccionar otra región para crear el clon (aunque en mi cuenta no tengo acceso a otras regiones):


Para ver más detalles se puede consultar la documentación oficial.
Autonomous Data Guard en distintas regiones con Keys administradas por el usuario
Autonomous Database es totalmente compatible con el uso de claves administradas por el usuario, aún con una base de datos Standby de Autonomous Data Guard ubicada en otra región.
Para ver más detalles se puede consultar la documentación oficial de Autonomous DataGuard.
Acceso a Directorios NFS
Ahora es posible adjuntar un sistema de archivos NFS a una base de datos autónoma. De esta forma se puede cargar datos desde Oracle Cloud Infrastructure File Storage o desde un NFS en un Data Center on-premise a una base de datos autónoma.
Para ver más detalles se puede consultar la documentación oficial.
Nueva Herramienta Data Transforms
Esta herramienta de integración de datos disponible desde el grupo de tareas "Data Studio" de Database Actions permite importar y transformar datos desde diversas fuentes de datos a Oracle Autonomous Database, todo en forma visual y sin necesidad de escribir código.
Para ver más detalles se puede consultar la documentación oficial.
Mejoras a Integración con GIT
Adiciones y mejoras para Cloud Code Repository en el paquete DBMS_CLOUD_REPO para la administración de branchs del repositorio (Git) y la exportación e instalación de esquemas.
Para ver más detalles se puede consultar la documentación oficial.
Mejoras de Diciembre de 2022
Soporte de Múltiples Data Catalog
A partir de diciembre es posible registrar una base de datos autónoma en mas de un servicio de Data Catalog de Oracle Cloud
Para ver más detalles se puede consultar la documentación oficial.
Incremento de Limites para los servicios Medium y High con AutoScaling
Si se encuentra habilitada la opción de auto-scaling para las OCPU de la instancia de base de datos autónomas, los limites de sentencias concurrentes para los servicios Medium y High se triplican, permitiendo mayor actividad en la base de datos.
Limites para Data Warehouse

Limites para Transaction Processing & JSON Database

Para ver más detalles se puede consultar la documentación oficial.
Uso de Credenciales en Paquetes
Ahora es posible usar un objeto de tipo Credencial para autenticar al usuario de los paquetes UTL_HTTP, UTL_SMPT y DBMS_LDAP.
Para ver la información específica en cada uno de ellos, consultar los siguientes artículos de la documentación:
- Use Credential Objects to set SMTP Authentication.
- Use Credential Objects to Set HTTP Authentication.
- PL/SQL Packages (includes information on DBMS_LDAP).
Uso de Pipelines para Exportación y Carga de Datos
Data Pipelines es una nueva característica que permite cargar datos desde un Object Store, o exportar datos a un Object Store.
Los Pipeline de carga de datos permiten realizar carga incremental de datos en forma continua, importando los datos a la base de datos tan pronto como ingresan al Object Store. Los Pipeline de exportación permiten exportar en forma continua a Object Store los datos que son ingresados a una tabla de base de datos.
Para ver más detalles se puede consultar la documentación oficial.
No hay comentarios.:
Publicar un comentario